기술 철학
현장에서 작동하는 AI를 설계합니다
트리플렛의 기술은 데모를 위한 구조가 아니라, 운영 중에도 무너지지 않는 구조를 전제로 설계되어 다음과 같은 공통 엔진 위에서 작동합니다.
모든 분석은 실시간성·안정성·확장성을 동시에 고려합니다.
데이터는 수집보다 판단으로 연결되는 구조를 우선합니다.
기술은 판단을 대신하지 않고, 판단의 근거를 남기는 역할에 머뭅니다.
현실의 움직임이 운영의 결정으로 이어지는 구조
현장의 움직임이 데이터로 변환되고, 운영의 결정으로 이어지는 과정을 설명합니다
1. 공간
카메라·센서가 현장의 움직임을 수집합니다.
 tech_step_01.png
tech_step_01.png
2. 데이터화
비식별 처리 후, 분석 가능한 구조로 변환합니다.
 tech_step_02.png
tech_step_02.png
3. 판단 구조
운영 판단에 바로 쓰이는 리포트와 알림을 제공합니다.
 tech_step_03.png
tech_step_03.png

현장을 이해하는
여섯 가지 엔진
트리플렛의 분석은 단일 알고리즘이 아닌, 상호 보완적인 모듈의 조합으로 작동합니다. 각 엔진은 독립적으로 배포되거나 파이프라인으로 결합됩니다.
Triplet DeepLounge Engine ❶
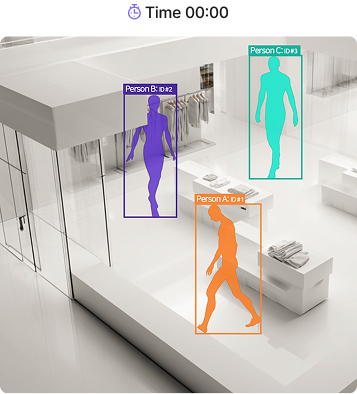
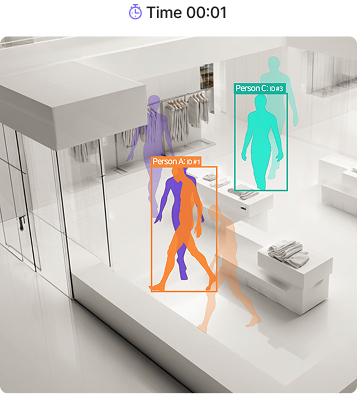
MOT 실시간 궤적 분석
- ID 기반 연속 추적
- 경로·체류·혼잡도 분석 데이터 확보
- 가림·겹침 상황에서도 안정 추적
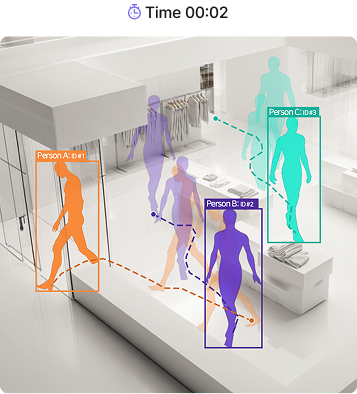
수십 명의 이동 궤적을 프레임 간 연속으로 추적합니다. 각 사람에게 고유 ID를 부여하고, 화면에 존재하는 동안 동일한 ID를 끊김 없이 유지합니다. 단순 감지(Detection)가 매 프레임마다 사람을 새로 찾는 방식이라면, 추적(Tracking)은 "현재 화면의 이 사람이 이전 프레임의 누구인가"를 연결합니다. 이 연속성이 있어야 이동 경로 분석, 체류 시간 측정, 실시간 혼잡도 계산이 가능합니다. 사람이 겹치거나, 구조물 뒤로 일시적으로 가려지거나, 빠르게 이동하는 상황에서도 ID는 유지됩니다. 대형 전시 공간(1,800평)과 100대 규모 카메라 환경에서도 안정적으로 동작이 검증되었습니다.
Triplet DeepLounge Engine ❷
Re-ID 다중 카메라 동선 연결
- 카메라 간 동일 인물 동선 연결
- 중복 없는 방문자 수 집계
- 비식별 외형 기반 재인식
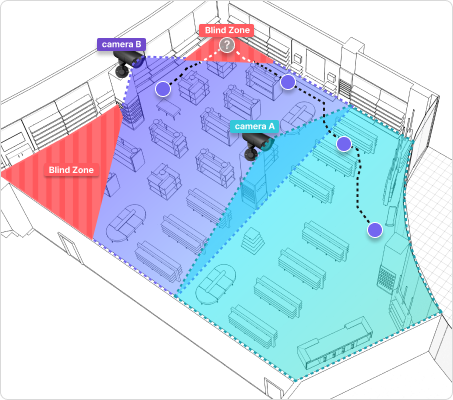
카메라 시야를 벗어난 사람을 외형 특징을 기반으로 다시 찾아 동선을 하나로 연결합니다. 얼굴 인식이 아닌 의상 색상·체형·보행 패턴 같은 외형 벡터를 비교하기 때문에 얼굴 데이터를 저장하지 않습니다. Re-ID가 없으면 동일 인물이 여러 카메라에 포착될 때 각각 다른 사람으로 집계됩니다. Re-ID를 적용하면 여러 카메라를 거친 이동 경로가 하나로 연결되어, 중복 없는 실제 방문자 수(Unique Visitor)를 정확히 산출할 수 있습니다. 카메라 간 시야가 겹치지 않는 사각지대(Blind Zone)에서도 재인식이 유지됩니다.

Triplet DeepLounge Engine ❸
Demographic AI 비저장 · 비식별
- 개인정보 저장없이 방문객 특성 추정
- 전신 기반 안정적 인식
- 다양한 카메라 환경 대응
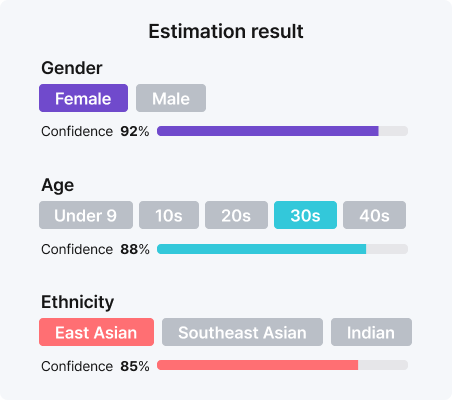
얼굴 이미지를 저장하지 않으면서 성별·연령대·인종을 실시간으로 추정합니다. 추론이 완료되는 즉시 원본 영상과 얼굴 데이터는 저장되지 않으며, 개인정보 보호 규정을 준수합니다. 얼굴만 보는 시스템과 달리 얼굴·몸통·하체를 포함한 전신 단위 특징을 함께 분석합니다. 마스크 착용·군중 혼잡·측면 각도 등으로 얼굴이 가려진 상황에서도 몸의 특징만으로 분류가 가능해 실제 현장 인식률이 높습니다. 어안 렌즈(fisheye)·탑뷰(top-view) 카메라 환경에서도 동작하도록 최적화되어, 천장 고정형 CCTV 환경에서도 바로 적용할 수 있습니다.

Triplet DeepLounge Engine ❹
Vision-Language Model 제로샷 위험 감지
- 상황 이해 기반 영상 인식
- 자연어 기반 행동·위험 감지
- 제로샷 기반 새로운 위험 판단
영상 장면을 언어로 이해합니다. 기존 컴퓨터 비전 모델이 사전에 등록된 클래스(헬멧·조끼 등)만 감지하는 것과 달리, VLM은 "보행 중 핸드폰을 사용하는 장면"처럼 자연어로 정의된 행동이나 위험을 그대로 감지할 수 있습니다. 이미지를 작은 단위로 분해해 시각 정보를 벡터로 변환하고, 이를 Projection Layer를 통해 언어 모델이 이해할 수 있는 형태로 연결합니다. 이후 대규모 언어 모델(LLM)이 시각 정보와 텍스트 지식을 결합해 장면의 의미를 해석합니다. 해당 기술은 Triplet OZO(안전 관리)와 Triplet KODA(경기 판정)의 핵심 추론 엔진으로 사용됩니다.
1. 영상 인식 & 토큰화

2. 시각 임베딩 생성

3. 시각-언어 공간 정렬
4. 언어 해석 및 출력

Triplet DeepLounge Engine ❺
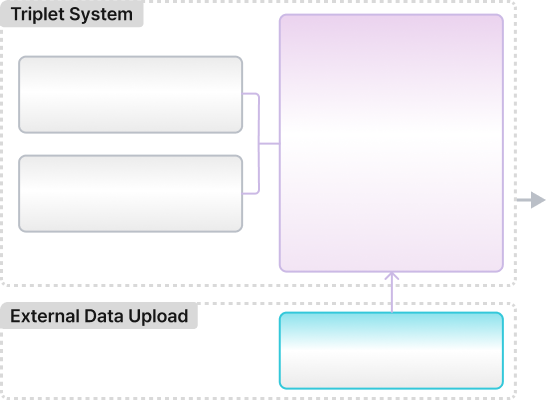
RAG 기반 공간 데이터 인사이트
- 공간 데이터 + 외부 데이터 교차 분석
- 자연어 질문으로 즉시 인사이트 도출
- 현장 담당자 직접 분석 가능
트리플렛 시스템은 이미 공간 분석 데이터(체류 시간, 이동 경로, 혼잡도)를 RAG 엔진에 내장하고 있습니다. 여기에 담당자가 보유한 외부 데이터(예: 매출 데이터, 고객 설문 등)를 추가 업로드하면, 자연어로 질문하는 것만으로 두 데이터를 교차 분석한 결과를 즉시 받을 수 있습니다. "체류가 길지만 매출 전환이 낮은 구역이 어디인지", "피크 시간대에 어느 동선이 막히는지"처럼 기존에는 데이터 분석가에게 맡겨야 했던 질문을 현장 담당자가 직접 실시간으로 해결할 수 있습니다.
Triplet DeepLounge Engine ❻
VLM 기반 텍스트 영상 검색
- 외형 묘사 텍스트로 영상 전체 검색
- 얼굴 DB 없이 즉시 활용 가능
- 인물 동선 및 이동 경로 자동 재구성
외형 묘사 텍스트 한 줄로 CCTV 영상 전체를 검색합니다. "붉은색 상의, 모자 착용, 검은색 하의"처럼 실종 접수 시 확보한 외형 묘사를 입력하면, VLM이 해당 외형과 유사한 인물이 등장한 영상 구간을 유사도 순으로 찾아냅니다. DB에 등록된 얼굴 없이도 즉시 활용할 수 있습니다. 수백 시간 분량의 영상을 수 초 안에 탐색하고, 해당 인물이 거쳐 간 카메라 경로를 시간순으로 재구성합니다. 실종자 수색, 용의자 동선 추적, 특정 외형 인원의 입장 이력 확인 등에 바로 적용됩니다.

실종자 수색
신고 시 확보된 외형 묘사를 기반으로 산악·공원·시설 내 CCTV를 동시에 검색합니다. 수백 시간 분량의 영상을 수 초 내에 탐색할 수 있습니다.

용의자 동선 추적
외형 묘사만으로 특정 인물이 이동한 카메라 경로를 시간순으로 재구성합니다. 얼굴이 등록되지 않은 인원도 외형 기반으로 추적할 수 있습니다.


보안은 옵션이 아니라,
기본 조건입니다
트리플렛은 공공·산업·대규모 시설 환경을 전제로 처음부터 보안과 비식별을 설계에 포함합니다.
- 영상 원본 저장 없이 비식별 데이터만 처리
- Edge 단계에서 마스킹 및 필터링 수행
- 온프레미스 / 프라이빗 클라우드 구성 지원
- 공공기관·실증·PoC 환경 대응 구조
트리플렛이 다른 이유
현장에서 작동하는 것과 데모에서 작동하는 것은 다릅니다.
같은 기술을 써도 결과가 다릅니다. 트리플렛은 수년간 실제 현장에서 마주한 문제들을 해결하며 쌓은 구현 경험이 있습니다. 그 경험이 정확도를 높이고, 예외 상황을 처리하고, 현장에서 멈추지 않는 시스템을 만듭니다.
Triplet Challenge ❶
범용 post-process로 어떤 현장에서도
SOTA 모델을 그대로 가져다 붙이면 고객사 도메인에서 Detection 자체가 잘 안 됩니다. 사람이 너무 많거나, 빠르게 이동하거나, 카메라 각도가 특수한 환경에서 ID 스위칭과 궤적 단절이 빈번하게 발생합니다.

트리플렛의 해법
트리플렛은 어떤 현장에서도 궤적이 끊기지 않습니다. Detection 품질이 들쑥날쑥해도 궤적을 안정적으로 유지하는 범용 post-process 알고리즘을 자체 개발했습니다. 현장별 밀도·속도·카메라 조건에 맞춘 튜닝으로 성능을 끌어올립니다. 1,800평·카메라 100대가 그 검증 결과입니다.
Triplet Challenge ❷
가장 어려운 유니폼 현장과 야간 현장에서의 검증

공개 데이터셋과 달리, 실제 현장은 훨씬 복잡합니다. 사람이 서로 가리고, 조명이 바뀌고, 카메라 각도도 일정하지 않습니다. 특히 동일한 유니폼을 입은 수십 명이 동시에 움직이는 환경에서는 색상이나 패턴으로 개인을 구별하는 것이 거의 불가능합니다.
트리플렛의 해법
트리플렛은 의상이 같으면 색상 대신 걸음걸이·체형·이동 궤적 같은 동작 기반 특징으로 구별합니다. 현장 데이터를 직접 수집해 해당 환경에 최적화된 특징 표현(feature representation)을 학습합니다. 야간·저조도에서도 동작합니다. IR(적외선) 영상에서도 Re-ID 성능이 유지되도록 구현해, 조명 없는 현장에서도 24시간 운영이 가능합니다.
Triplet Challenge ❸
화면 속 100px, 엄지손가락만 한 크기의 사람도 수십 대 동시에 실시간으로
현장의 CCTV는 넓은 공간을 보기 위해 설치됩니다. FHD 영상에서도 사람은 대부분 100px 이하의 작은 객체로 관측되어 얼굴 표정, 손동작, 자세 디테일이 모두 사라집니다. 즉, VLM이 행동을 이해하는 데 필요한 feature 자체가 존재하지 않는 상태입니다. 여기에 수십 대 카메라를 동시에 처리하려면 연산량 역시 현실적으로 감당하기 어렵습니다.

트리플렛의 해법
트리플렛은 이 조건에서 실시간 감지를 가능하게 했습니다. 화면 전체를 처리하지 않고, 이상행동이 의심되는 사람을 먼저 추적한 뒤 그 사람에게만 집중해서 VLM 추론을 수행합니다. 필요한 대상과 순간만 골라내기 때문에 연산량이 크게 줄고, 해상도 문제도 동시에 해결됩니다.
Triplet Challenge ❹
위반 감지에서 한 발 더, MEA 1회 이하의 정밀 집계

VLM은 특정 행동을 감지할 수 있습니다. 하지만 빠르게 반복되는 상황에서 같은 이벤트가 여러 프레임에 걸쳐 나타날 때, 이를 1회로 볼 것인지 여러 번으로 볼 것인지는 전혀 다른 문제입니다. 이 기준이 없으면 이벤트 횟수 자체를 정확히 집계할 수 없습니다.
트리플렛의 해법
트리플렛은 감지에서 멈추지 않고 정확한 횟수 집계까지 해냅니다. 동일 이벤트를 하나로 묶는 post-process를 통해 중복을 제거하고 실제 발생 횟수만 계산합니다. Mean Event Accuracy(MEA) 1회 이하 수준으로, 단순 감지를 넘어 실제 심의에 쓸 수 있는 데이터를 만들어냅니다.
96 × 96